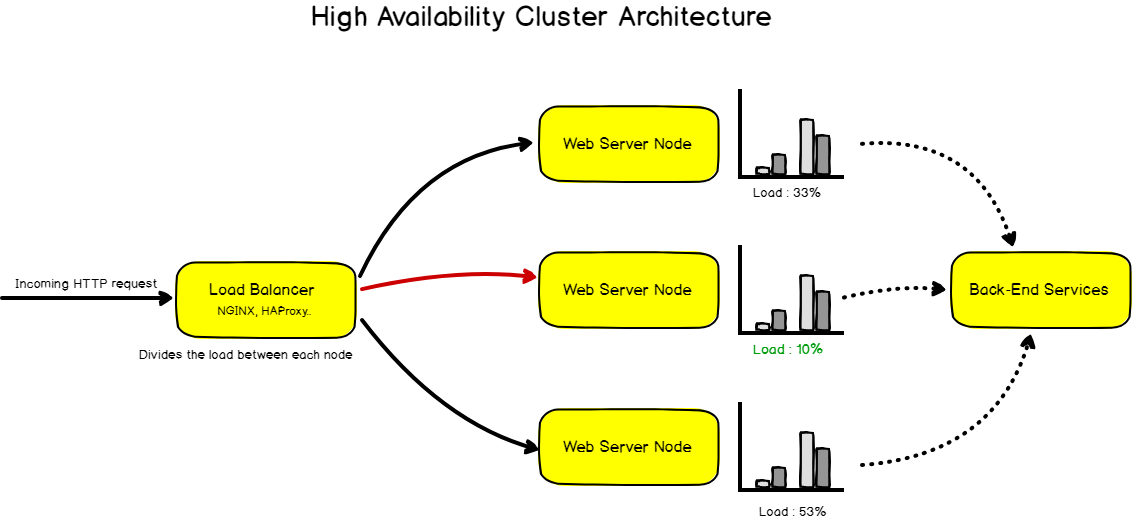
A word about high availability
A high-availability cluster is a group of servers designed and assembled in a way that provides permanent availability and redundancy of the services provided.
Let’s say that you are building a simple web application. On launch, you get a traffic of a thousand page views per day, a load that any decent HTTP server can handle without any trouble. Suddenly, your traffic skyrockets and jumps to a million page views per day. In this case, your basic HTTP server can’t handle the load all by itself and needs additional resources.
A solution to this problem would be to implement a HA cluster architecture.
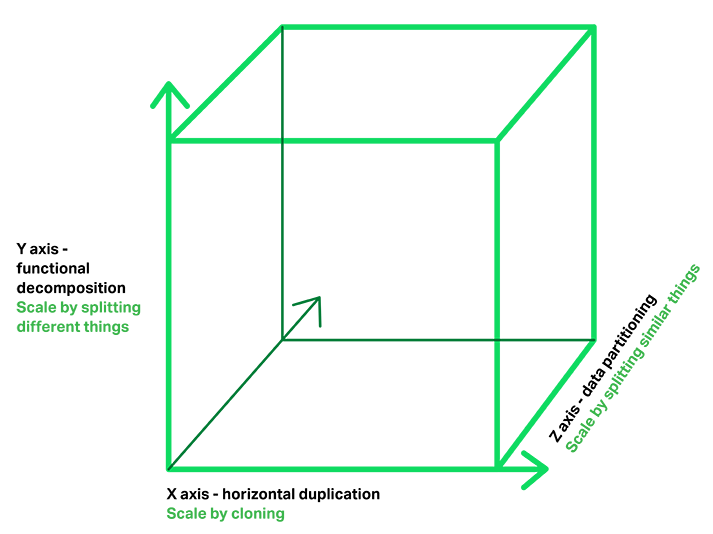
Scale cube
Microservices Architecture pattern corresponds to the Y‑axis scaling of the Scale Cube. The other two scaling axes are X‑axis scaling, which consists of running multiple identical copies of the application behind a load balancer, and Z‑axis scaling (or data partitioning), where an attribute of the request (for example, the primary key of a row or identity of a customer) is used to route the request to a particular server.

Quote
Imagine that you are buying a brand new car. You got a Nissan car which can accommodate 4 people in it. Now, say you and 10 of your friends need to go for a vacation. What would you do?
- Would you buy a bigger car? — Vertical Scaling
- Would you buy one more Nissan car? — Horizontal Scaling
How High Availability Works
To create a highly available system, three characteristics should be present:
- Redundancy
- Monitoring
- Failover
In general, a high availability system works by having more components than it needs, performing regular checks to make sure each component is working properly, and if one fails, switching it out for one that is working.
Load balancing
Services are often used in environments where scaling and availability are expected. Traditionally, network devices provide load balancing functionality. But in a microservices environment, it is more typical to see this moved into the software layer of the macro-architecture’s infrastructure.
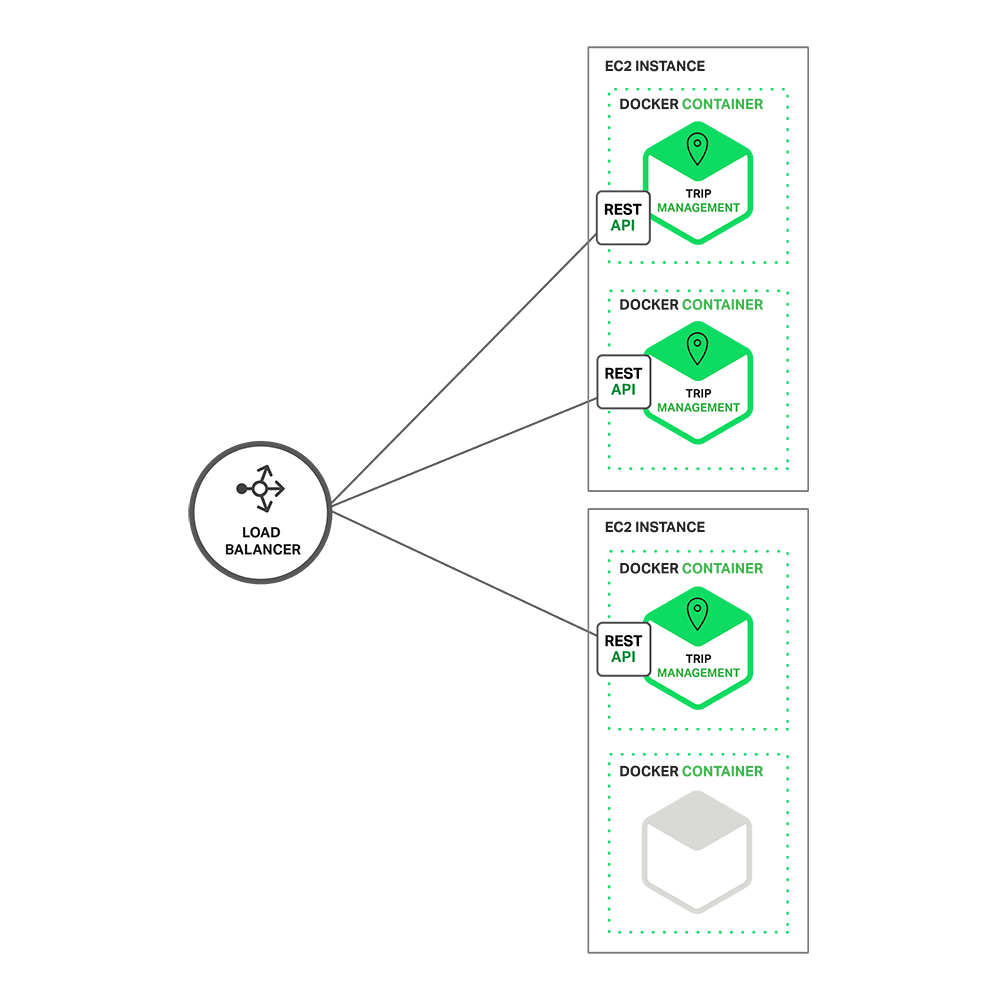
Applications typically use the three types of scaling together. Y‑axis scaling decomposes the application into microservices as shown above in the first figure in this section. At runtime, X‑axis scaling runs multiple instances of each service behind a load balancer for throughput and availability. Some applications might also use Z‑axis scaling to partition the services. The following diagram shows how the Trip Management service might be deployed with Docker running on Amazon EC2.
Redundancy
In computing, redundancy means that there are multiple components that can perform the same task. This eliminates the single point of failure problem by allowing a second server to take over a task if the first one goes down or becomes disabled. Because the same tasks are handled by multiple components, replication is also critical. In a replicated system, the components that handle the same tasks communicate with one another to ensure that they have the same information at all times.
For example, suppose you have a LAMP stack running a website hosted on a single Linode. If the database in the LAMP stack were to stop working, PHP may be unable to perform queries properly, and your website will be unavailable to display the requested content or handle user authentication.
In a highly available configuration, however, this problem is mitigated because the databases are distributed across several servers. If one of the database servers becomes disabled for any reason, data can still be read from one of the others, and because the databases are replicated, any one of them can serve the same information. Even if one database becomes disabled, another can take its place.
Resiliency
Resiliency means remaining stable even in the face of errors. Retries, deadlines, default behaviors, caching behaviors, and queuing are a few of the ways microservices provide resiliency.
Just like load balancing, some part of resiliency is a perfect match for the infrastructure to handle at the edge— such a retries and circuit breaking (automatic error responses for services exceeding a failure threshold in the recent past).
However, the individual service should consider what resiliency role it should play internally. For example,an account signup system, where losing a signup equates to losing money, should take ownership of ensuring that every signup goes through — even if it means a delayed creation that results in an email to the account owner once successful. Internal queuing and management of pending signups may be best managed directly by this mission-critical service.
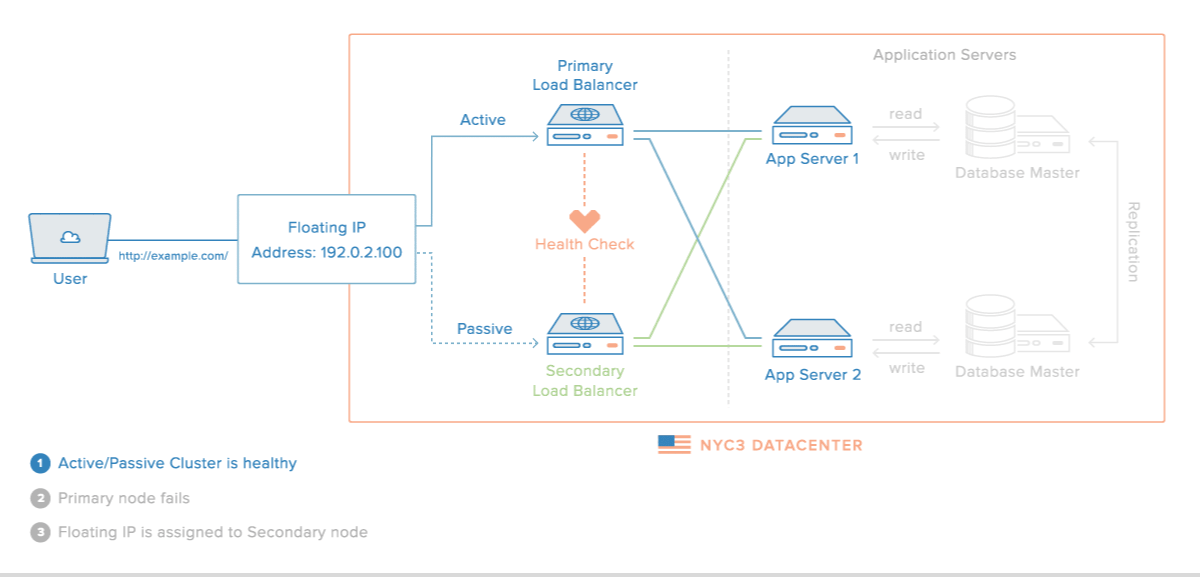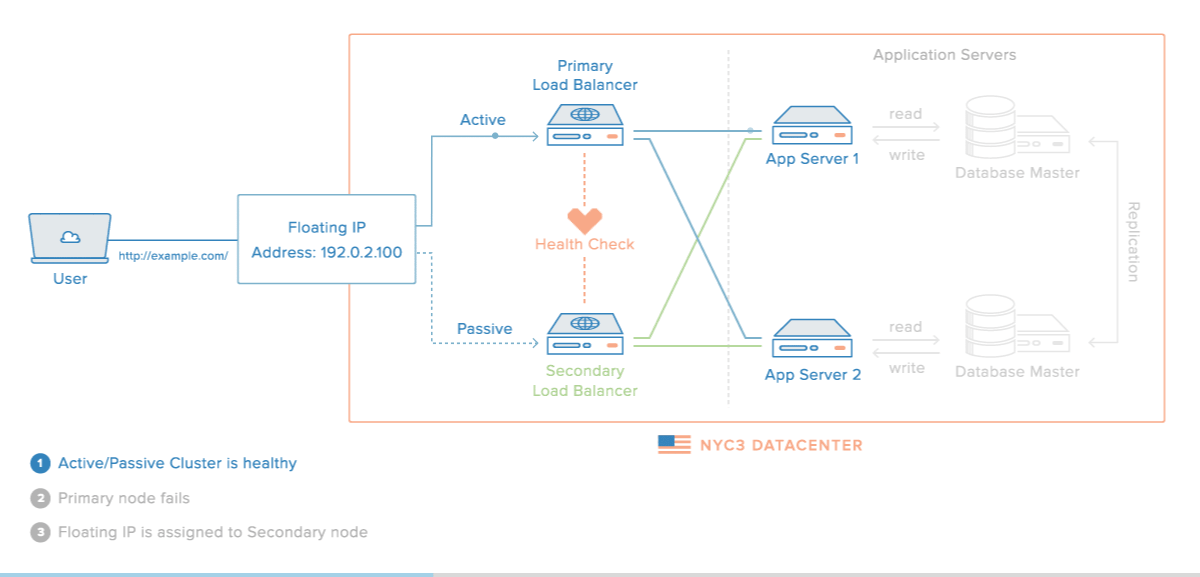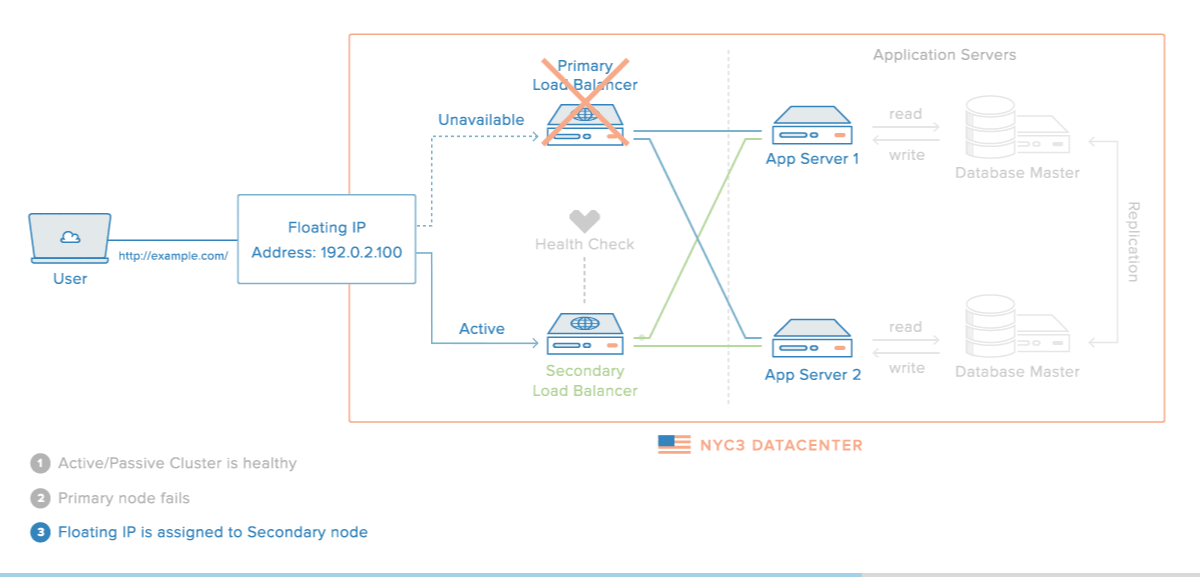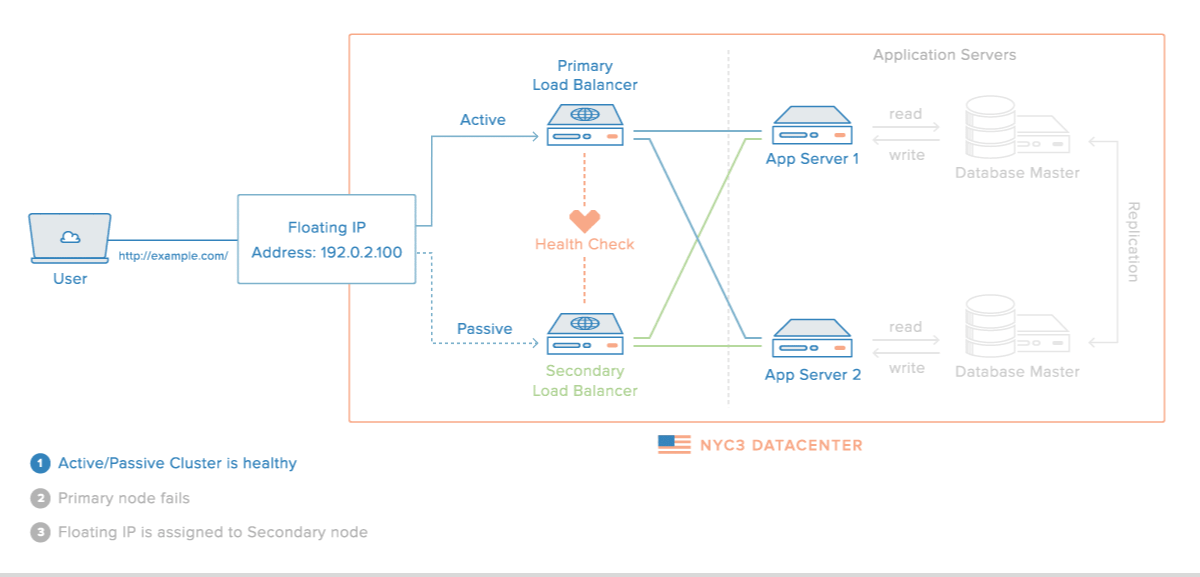
Elastic IPs / Floating IPs
Elastic / floating IPs are a kind of virtual IP address that can be dynamically routed to any server in the same network.
Multiple servers can own the same Floating IP address, but it can only be active on one server at any given time.
Floating IPs can be used to:
- Implement failover in a high-availability cluster
- Implement zero-downtime Continuous Deployment
- Keep the same IP address on a server, even when it is being relocated in the data center
A Floating IP address has a dynamic, one-to-one relation with an "Anchor" IP address. The Anchor IP address is the primary IP address of the server that the Floating IP address is being routed to.
This sounds complicated, but what it really means is that the Floating IP just piggybacks on another IP address, that you can choose and change at your leisure.
Amazon AWS calls this fuctionality Elastic IP. Google Compute Engine and Digital Ocean use the term Floating IPs.