Elements of a CI/CD pipeline
A CI/CD pipeline may sound like overhead but it really isn’t. It’s essentially a runnable specification of the steps that need to be performed in order to deliver a new version of a software product. In the absence of an automated pipeline, engineers would still need to perform these steps manually, and hence far less productively.
Most software releases go through a couple of typical stages:
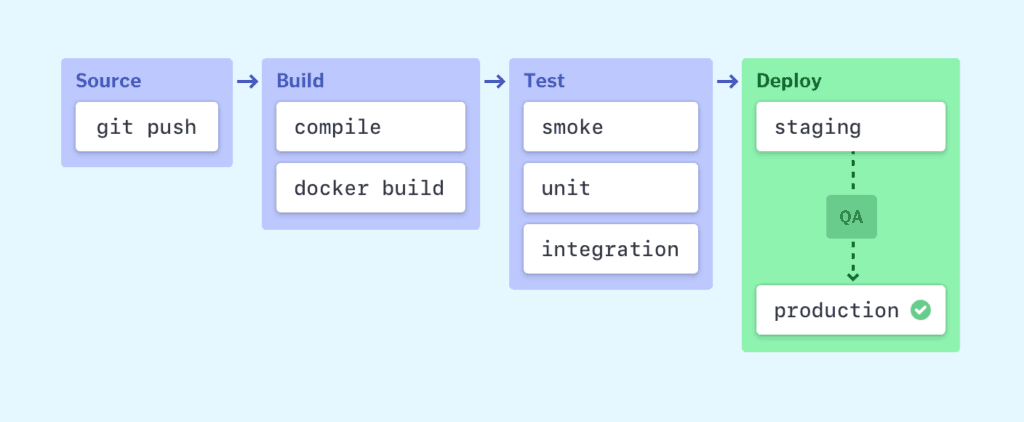
Failure in each stage typically triggers a notification—via email, Slack, etc.—to let the responsible developers know about the cause. Otherwise notifications are usually configured to be sent to the whole team after each successful deploy to production.
Source stage
In most cases a pipeline run is triggered by a source code repository. A change in code triggers a notification to the CI/CD tool, which runs the corresponding pipeline. Other common triggers include automatically scheduled or user-initiated workflows, as well as results of other pipelines.
Build stage
We combine the source code and its dependencies to build a runnable instance of our product that we can potentially ship to our end users. Programs written in languages such as Java, C/C++, or Go need to be compiled, whereas Ruby, Python and JavaScript programs work without this step.
Regardless of the language, cloud-native software is typically deployed with Docker, in which case this stage of the CI/CD pipeline builds the Docker containers.
Failure to pass the build stage is an indicator of a fundamental problem in the configuration of our project and it’s best to address it immediately.
Test stage
In this phase we run automated tests to validate the correctness of our code and the behavior of our product. The test stage acts as a safety net that prevents easily reproducible bugs from reaching the end users.
The responsibility of writing tests falls on the developers, and is best done while we write new code in the process of test- or behavior-driven development.
Depending on the size and complexity of the project, this phase can last from seconds to hours. Many large-scale projects run tests in multiple stages, starting with smoke tests that perform quick sanity checks to end-to-end integration tests that test the entire system from the user’s point of view. A large test suite is typically parallelized to reduce run time.
Failure during the test stage exposes problems in code that developers didn’t foresee when writing the code. It’s essential for this stage to produce feedback to developers quickly, while the problem space is still fresh in their minds and they can maintain the state of flow.
Deploy stages
Once we have a built a runnable instance of our code that has passed all predefined tests, we’re ready to deploy it. There are usually multiple deploy environments, for example a “beta” or “staging” environment which is used internally by the product team, and a “production” environment for end users.
Teams that have embraced the Agile model of development—which is guided by tests and real-time monitoring—usually deploy work-in-progress manually to a staging environment for additional manual testing and review, and automatically deploy approved changes from the master branch to production.
Example of CI/CD pipeline
A pipeline can start very simple. Here’s an example of a pipeline for a Go project which compiles the code, checks code style and runs automated tests in two parallel jobs:

Additional benefits of pipelines
Having a CI/CD pipeline has more positive effects than simply making what was previously done a little bit more efficient:
- Developers can stay focused on writing code and monitoring the behavior of the system in production.
- QA and product stakeholders have easy access to the latest, or any, version of the system.
- Product updates are not stressful.
- Logs of all code changes, test and deployments are available for inspection at any time.
- Rolling back to a previous version in the event of a problem is a routine push-button action.
- A fast feedback loop helps build an organizational culture of learning and responsibility.
What makes a good pipeline?
A good CI/CD pipeline is fast, reliable and accurate.
Speed
Speed manifests itself in a number of ways:
- How quickly do we get feedback on the correctness of our work? If it’s longer than the time it takes to get a cup of coffee, pushing code to CI is the equivalent of asking a developer to join a meeting in the middle of solving a problem. Developers will work less effectively due to inevitable context switching.
- How long does it take us to build, test and deploy a simple code commit? For example, a total time of one hour for CI and deployment means that the entire engineering team has a hard limit of up to seven deploys for the whole day. This causes developers to opt for less frequent and more risky deployments, instead of the rapid change that businesses today need.
Reliability
A reliable pipeline always produces the same output for a given input, and with no oscillations in runtime. Intermittent failures cause intense frustration among developers.
Good things to do
When the master is broken, drop what you’re doing and fix it. Maintain a “no broken windows” policy on the pipeline.
Run fast and fundamental tests first. If you have a large test suite, it’s common practice to parallelize it to reduce the amount of time it takes to run it. However, it doesn’t make sense to run all the time-consuming UI tests if some essential unit or code quality tests have failed. Instead, it’s best to set up a pipeline with multiple stages in which fast and fundamental tests—such as security scanning and unit tests—run first, and only once they pass does the pipeline move on to integration or API tests, and finally UI tests.
Always use exactly the same environment. A CI/CD pipeline can’t be reliable if a pipeline run modifies the environment in which the next pipeline will run. It’s best that each workflow run starts from exactly the same, clean and isolated environment.
Build in quality checking. For example, there are open source tools that provide static code analysis for every major programming language, covering everything from code style to security scanning. Run these tools within your CI/CD pipeline and free up brainpower for creative problem-solving.
Include pull requests. There’s no reason why a CI/CD pipeline should be limited to one or a few branches. By running the standard set of tests against every branch and corresponding pull request, contributors can identify issues before engaging in peer review, or worse, before the point of integration with the master branch. The outcome of this practice is that merging any pull request becomes a non-event.
Peer-review each pull request. No CI/CD pipeline can fully replace the need to review new code. There may be times when the change is indeed so trivial that peer review is a waste of time; however, it’s best to set the norm that every pull request needs another pair of eyes, and make exceptions only when it makes sense, rather than vice versa. Peer code review is a key element in building a strong, egoless engineering culture of collaborative problem solving.