Database pooling
A connection pool is a cache of database connections maintained so that the connections can be reused when future requests to the database are required. Connection pools are used to enhance the performance of executing commands on a database. Opening and maintaining a database connection for each user, especially requests made to a dynamic database-driven website application, is costly and wastes resources.
In connection pooling, after a connection is created, it is placed in the pool and it is used again so that a new connection does not have to be established. If all the connections are being used, a new connection is made and is added to the pool. Connection pooling also cuts down on the amount of time a user must wait to establish a connection to the database.
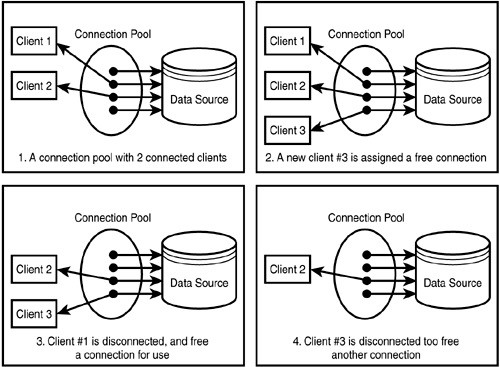
In short, connection pooling helps reduce the number of resources required for connecting to a database, speeding up the connection. Instead of the old way, where you would need to open a connection with the correct credentials each time you make a request to the DB, connection pooling does just that. It pools the connections to the DB, maintaining a connection to the DB and greatly reducing the number of connections that must be opened.
The pooler maintains ownership of the physical connection with the DB by keeping a set of active connections alive. Whenever a user cals on a connection, the pooler searches for an available connection, using that one rather than opening a new one. When the application calls to Close the connection, that connection is instead returned to the pool of connections. So next time there’s a call to the DB, that one will already be opened.
By maintaining an open pool of connections to the DB, connection pooling is essential for speedy database connectivity.
Replication
Replication is the process to copy data from one server to another. It’s generally done so as to prevent data loss in case a server fails or to distribute the incoming load to multiple servers which have same data. The result is a distributed database in which users can quickly access data relevant to their tasks without interfering with the work of others.
Data replication design becomes a balancing act between system performance and data consistency.
Database replication can be done in at least three different ways. In snapshot replication, data on one server is simply copied to another server or to another database on the same server; in merging replication, data from two or more databases is combined into a single database; and, in transactional replication, user systems receive full initial copies of the database and then receive periodic updates as data changes.
With database replication, the focus is usually on database scale out for queries, while database mirroring, in which log extracts form the basis for incremental database updates from the principal server, is typically implemented to provide hot standby or disaster recovery capabilities.

Database servers can work together to allow a second server to take over quickly if the primary server fails (high availability), or to allow several computers to serve the same data (load balancing). Ideally, database servers could work together seamlessly. Web servers serving static web pages can be combined quite easily by merely load-balancing web requests to multiple machines. In fact, read-only database servers can be combined relatively easily too. Unfortunately, most database servers have a read/write mix of requests, and read/write servers are much harder to combine. This is because though read-only data needs to be placed on each server only once, a write to any server has to be propagated to all servers so that future read requests to those servers return consistent results.
Database replication vs. mirroring
In relational database mirroring, complete backups of databases are maintained for use in the case that the primary database fails. Mirrors, in effect, serve as hot standby databases. While data mirroring is sometimes positioned as an alternative approach to data replication, it is actually a form of data replication.
Further reading