Motivation
Monitoring gives us the ability to understand our system’s health, address performance and availability issues based on data.
Couple of reasons why you need monitoring:
- You don’t have software ownership if you don’t monitor it.
- You can’t say how much of availability your service had in the event of an outage.
- You have no clue if your service is getting slower over time and why it does so.
- Was memory high or was a dependency which affected your service?
- Or was a dependency of your service dependency?
- It might takes months or even years to investigate why a portion of your customers were getting logged out of your website, why they couldn’t list their account preferences during the night and so on.
- During outages, engineers need to use data to take decisions, otherwise they will always have to depend exclusively from the opinion and feelings of the most senior engineer around.
- The lack of monitoring is a massive DevOps anti-pattern.

While it’s true that a decade ago, up/down checks might’ve been all a “monitoring” tool would have been capable of, in the recent years “monitoring” tools have evolved greatly, to the point where many, many, many people no longer think of monitoring as just external pings.
While they might still call it “monitoring”, the methods and tools they use are more powerful and streamlined. Time series, logs and traces are all more in vogue than ever these days and are forms of “whitebox monitoring”, which refers to a category of monitoring based on the information derived from the internals of systems.
Quote
Meeting the customer’s expectations means — resolving the incident as soon as possible. But what about exceeding their expectations? This is where our proactive monitoring mechanism comes into play, where we foresee an incident before it starts and proactively alert our frontline support to be ready: ”There’s a Storm Coming”.
Blackbox vs. whitebox

-
Blackbox monitoring — that is, monitoring a system from the outside by treating it as a blackbox — is something that is very good at answering the; what is broken and alerting about a problem that’s already occurring (and ideally end user-impacting).
-
Whitebox monitoring, on the other hand, is fantastic for the signals we can anticipate in advance and be on the lookout for. In other words, whitebox monitoring is for the known, hard failure modes of a system, the sort that lend themselves well toward exhibiting any deviation in a dashboardable manner, as it were.
The Four Golden Signals
The Google Site Reliability Engineering book defined the term "the four golden signals"; i.e latency, traffic, errors, and saturation.
- Error Rate: Because errors immediately affect customers.
- Response time: Because slow is the new down.
- Throughput: The traffic helps you to understand the context of increased error rates and the latency too.
- Saturation & Utilization: It tells how full your service is.
- If the Memory usage is 95%, can your response time keep stable?
- Processes: Threads Used, State, Running and Blocked
- Disk I/O Utilization.

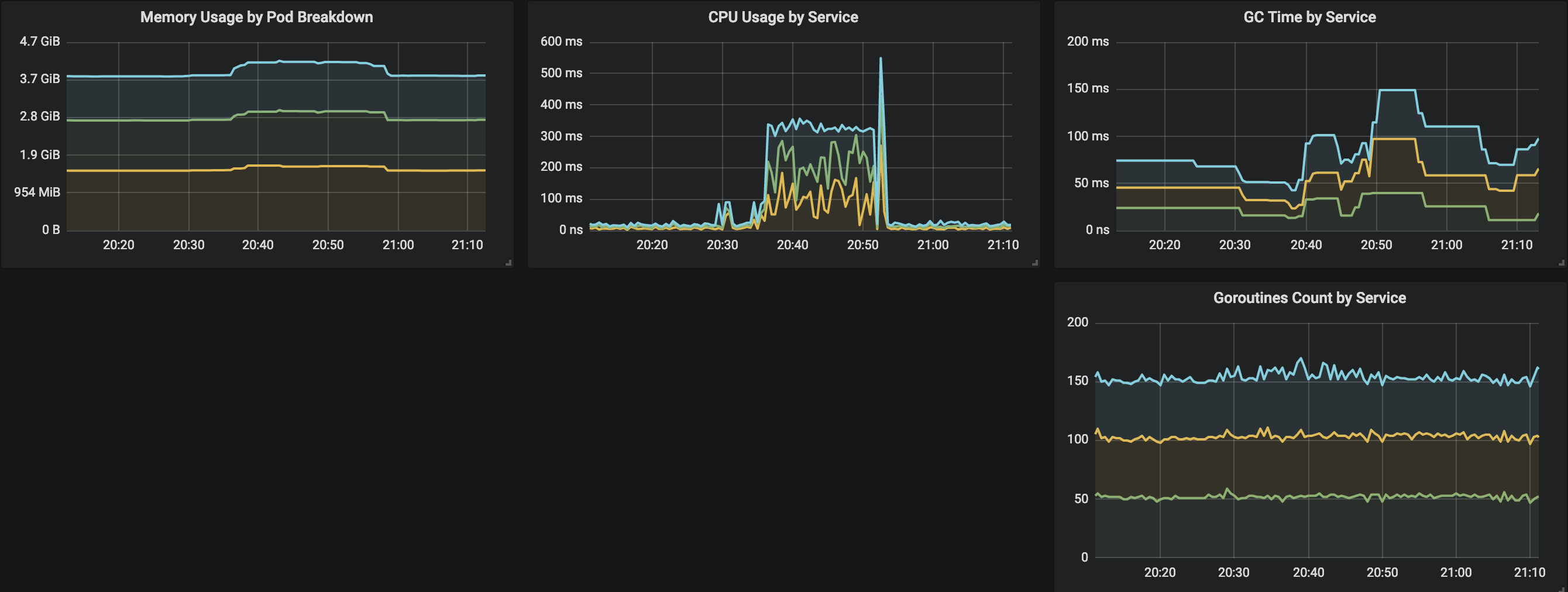
Error Rate, Response time and Throughput
Full size image
Saturation and Utilization
Full size image
In general, we tend to measure at three levels: network, machine, and application. Application metrics are usually the hardest, yet most important, of the three.
Quote
We have a ton of metrics. We try to collect everything but the vast majority of these metrics are never looked at. It leads to a case of severe metric fatigue to the point where some of our engineers now don’t see the point of adding new metrics to the mix, because why bother when only a handful are ever really used?
What to alert?
Alerts should be set for high response times and error rates. Ideally alerts should page on-call engineers when customers are affected.
For capacity they should detect when hosts run out of resources that will lead to an outage, for example: DiskWillFillIn4Hours, SSLCertificateWillExpireIn2Days and so on.
Avoid paging on-call engineers on root causes or low thresholds, just to name a few examples: NodeCPUTooHigh, NodeMemoryTooHigh, ConnectionRefused. Instead do over symptoms, tell what’s broken — TooManySlowCustomersQueries, TooManyCustomersCheckoutErrors.
It does not end here, alerts should link to relevant dashboards and consoles that answer the basic questions about the service being alerted.
If you use static alerting, don’t forget the lower bound alerts, such as near zero requests per second or latency, as these often mean something is wrong, even at 3 AM. when traffic is light.
In addition to alerting, you should also visualize these signals.
Info
Your monitoring system should address two questions: what’s broken, and why?
The “what’s broken” indicates the symptom; the “why” indicates a (possibly intermediate) cause.
“What” versus “why” is one of the most important distinctions in writing good monitoring with maximum signal and minimum noise.
Write Runbooks
Typically, a runbook contains procedures to troubleshoot systems. They should link to dashboards where service metrics, logs and traces can be found. Reduce MTTR (Mean Time to Resolve) by attaching runbooks to every alert on your system.
For recurring issues in DevOps and IT, runbooks are the instructions for resolving those incidents. Runbooks are used to spread organizational knowledge as companies scale and more people need to take on-call responsibilities for services they didn’t write. They’re a way to surface instructions faster and give context to alert data in real-time. At 3 AM, the last thing you want is an on-call team shuffling through numerous tools and data, simply trying to identify the cause of an issue.
Runbooks served automatically alongside an alert can drastically reduce the time spent identifying incidents and responding to them. Thorough runbook documentation can help on-call responders fix issues for systems they’ve never seen. Or, in order to fix the problem, they can quickly see which services or tools they’ll need access to. And, if they don’t have access to those applications or services, they can easily reroute the issue to the right person.
While it can seem like a hassle to build out a runbook repository and keep runbooks up-to-date, it’ll pay large dividends toward service reliability and incident remediation speed over time.
Conclusion
Monitoring is the bottom layer of the Hierarchy of Production Needs. It is a basic requirement to running a service in production, without it, service owners can’t tell whether the service is even working.

Further reading